Sistema de scoring de riesgo crediticio: de MVP a Producción
Este proyecto narra la evolución técnica de un sistema de scoring crediticio, desde un prototipo inicial (MVP) hasta su reingeniería completa como una arquitectura de Machine Learning robusta. Se enfoca en la resolución de sesgos metodológicos (Data Leakage) y la implementación de pipelines de código escalables para automatizar la decisión de otorgamiento de créditos.
1. El desafío de negocio
La institución financiera enfrentaba un cuello de botella operativo crítico: el 100% de las solicitudes de crédito eran revisadas manualmente por analistas humanos. Esto resultaba en tiempos de respuesta lentos y una tasa de impago creciente debido a la subjetividad en la evaluación.
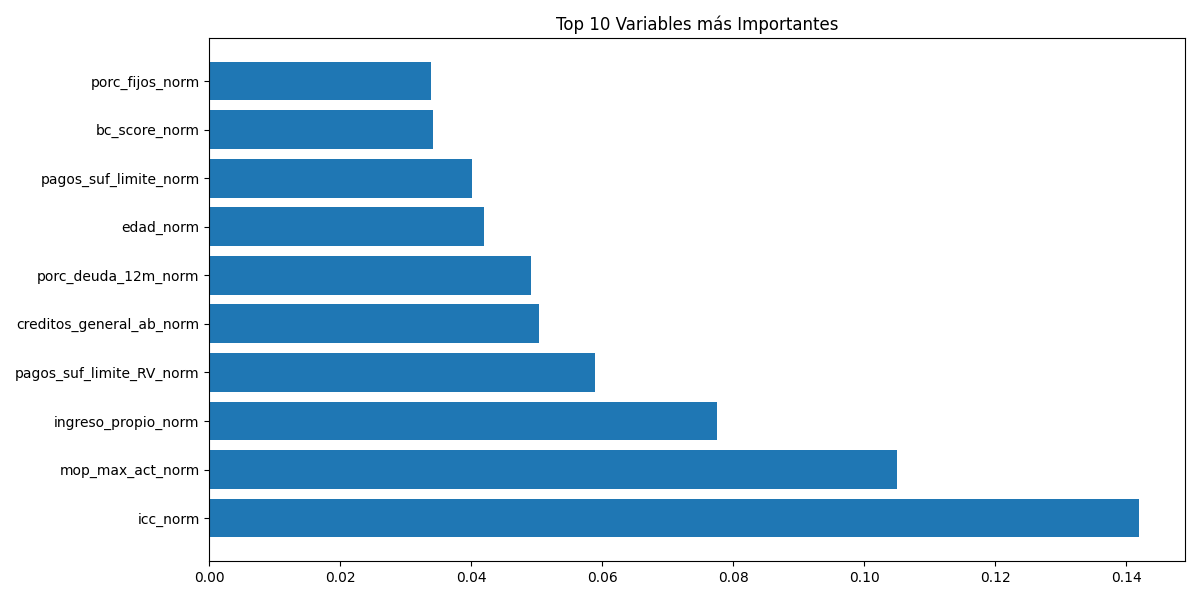
El objetivo fue desarrollar un algoritmo capaz de discriminar matemáticamente entre buenos y malos pagadores para automatizar el proceso de originación sin depender exclusivamente del criterio humano.
2. Fase 1: prototipado y diagnóstico
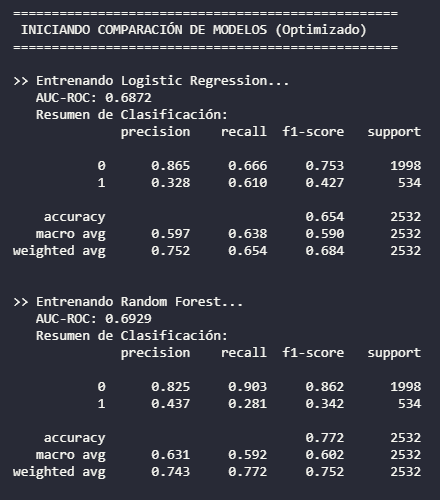
Inicialmente, se desarrolló un MVP (Producto Viable Mínimo) para validar la viabilidad del uso de datos demográficos y de comportamiento. Se probaron modelos base como Regresión Logística y Árboles de Decisión.
El hallazgo crítico: durante la auditoría del MVP, detecté un problema de *Data Leakage* (fuga de información) en el preprocesamiento: la técnica de balanceo SMOTE se estaba aplicando a todo el dataset antes de la validación cruzada, inflando artificialmente las métricas de éxito. Esto motivó una reingeniería total del código.
3. Fase 2: reingeniería y arquitectura
Para solucionar los sesgos y garantizar escalabilidad, refactoricé el código monolítico hacia una Arquitectura Orientada a Objetos y Pipelines de Scikit-Learn.
Implementé `ImbPipeline` para asegurar que el sobremuestreo (SMOTE) se aplicara estrictamente dentro de los pliegues de entrenamiento de la Validación Cruzada, garantizando que el modelo nunca viera datos sintéticos durante su evaluación.
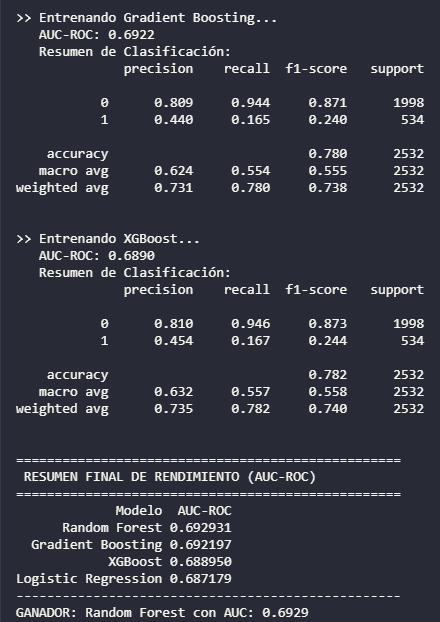
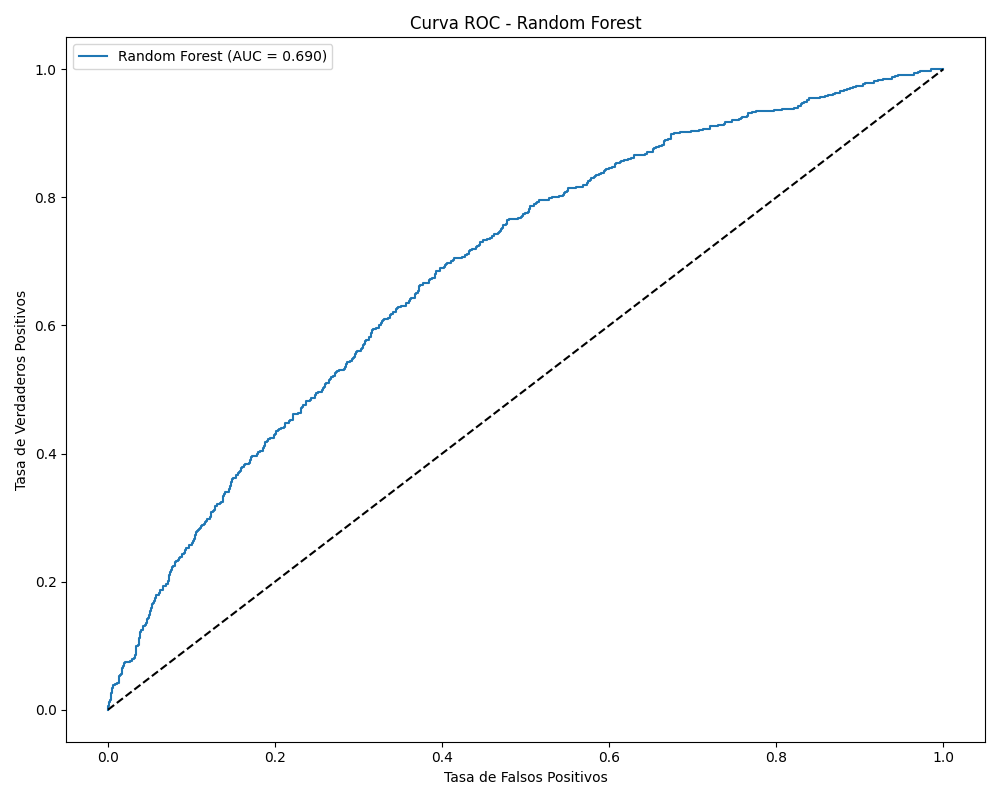
El resultado fue un modelo Random Forest estabilizado con un AUC-ROC de 0.69, optimizado para manejar datos reales con ruido e imperfecciones.
4. Resultados técnicos y estrategia
Métricas clave: el modelo final validado ofrece una precisión del 87% en la identificación de buenos clientes (minimizando la pérdida de oportunidades de negocio) y alcanza un Recall del 61% en la detección de posibles impagos utilizando Regresión Logística.
Automatización (Regla 80/20): se diseñó una matriz de decisión para optimizar el flujo operativo:
• Aprobación automática (Low Risk): probabilidad de impago < 20%.
• Rechazo automático (High Risk): probabilidad de impago > 80%.
• Revisión manual: limitada exclusivamente al segmento intermedio (20-80%), lo que proyecta una reducción del 60% en la carga de trabajo de los analistas.
Este proyecto no solo optimizó la precisión técnica, sino que redujo el cuello de botella operativo del equipo de crédito, permitiéndoles enfocar su tiempo humano únicamente en el 20% de los casos más complejos y dudosos, acelerando el Time-to-Market de los créditos pre-aprobados.