De archivos PDF a Vectores: el reto de la ingeniería de datos en la era de la IA
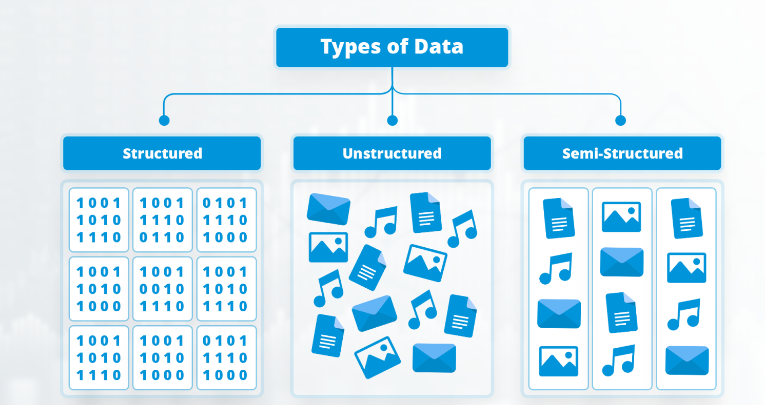
Hay una frase muy cierta en nuestra industria: 'Garbage in, garbage out' (Basura entra, basura sale). Nunca ha sido tan relevante como ahora en la era de los Modelos de Lenguaje (LLMs).
Es muy fácil crear una demo de un chatbot que responda preguntas sobre un archivo de texto limpio. Pero el mundo real corporativo no vive en archivos de texto planos. Vive en PDFs escaneados de hace 10 años, en hojas de cálculo con celdas combinadas y en imágenes de facturas.
Si intentas alimentar a una IA con esa 'basura' sin procesar, obtendrás un sistema caro e inútil. Aquí es donde la Ingeniería de Datos se vuelve el verdadero héroe silencioso.
El desafío de los datos No Estructurados
En mi proyecto más reciente de IA para el sector educativo, me enfrenté a una realidad común: la normativa institucional estaba atrapada en más de 1,500 documentos PDF. Muchos eran digitales, pero otros eran simples escaneos (imágenes) de reglamentos firmados en los años 90.
Para una computadora, una imagen de un texto es solo una matriz de píxeles, no información semántica.
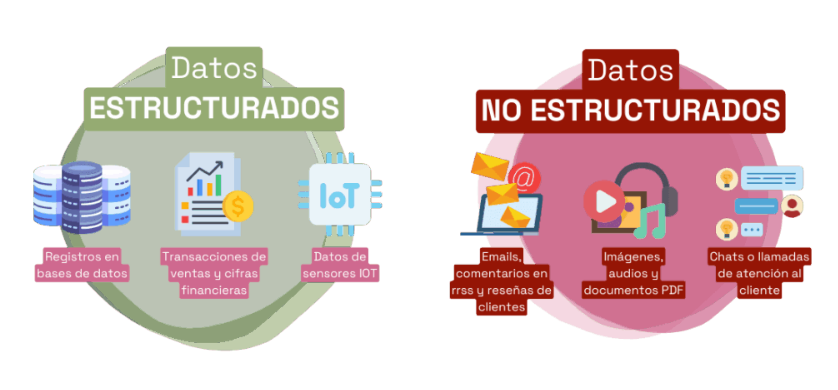
Datos para procesamiento vectorial
La solución: Un pipeline de ingesta robusto
Para resolver esto, diseñé un flujo de trabajo (Pipeline ETL) enfocado en la extracción y limpieza profunda antes de siquiera pensar en la IA:
1. OCR (Reconocimiento Óptico de Caracteres): utilicé Tesseract OCR para 'leer' las imágenes dentro de los PDFs. No basta con pasar la herramienta; hay que pre-procesar la imagen (aumentar contraste, eliminar ruido) para que el texto extraído sea fiel al original.
2. Limpieza y Chunking: un reglamento de 100 páginas no cabe en la memoria de contexto de un modelo. El secreto está en dividir el texto en fragmentos lógicos (chunks) —por ejemplo, por artículo o párrafo— manteniendo el contexto.
3. Vectorización (Embeddings): finalmente, convertimos esos fragmentos de texto en números (vectores) que representan su significado semántico y los almacenamos en ChromaDB. Esto permite que cuando alguien pregunte por 'becas', el sistema encuentre los artículos relacionados, aunque no usen exactamente la palabra 'beca'.
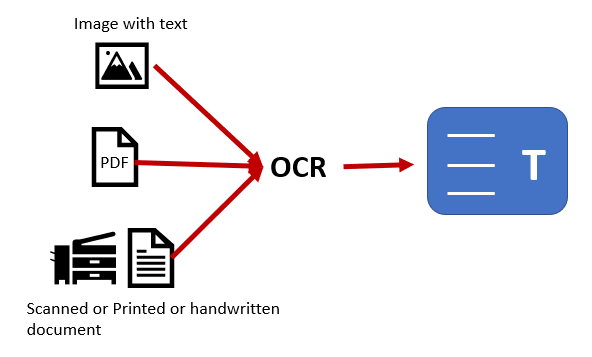
Transformación: de documento físico a base de datos vectorial.
Por qué esto importa para tu negocio
Muchas consultoras te venderán la 'magia' de la IA, pero fallarán en la implementación porque subestiman la suciedad de los datos reales.
Un Arquitecto de Datos entiende que el 80% del éxito de un proyecto de IA ocurre antes de que el modelo genere la primera palabra. Si tus datos no están limpios, estructurados y accesibles, la mejor IA del mundo no podrá ayudarte.
Conclusión
La Ingeniería de Datos moderna ha evolucionado. Ya no se trata solo de mover tablas de SQL a SQL. Ahora se trata de entender visión por computadora (OCR), procesamiento de lenguaje natural (NLP) y álgebra lineal (Vectores) para construir los cimientos sobre los que operará la inteligencia de tu empresa.