RAG vs. Fine-Tuning: ¿por qué tu empresa no necesita 'reentrenar' un modelo?
La fiebre por la Inteligencia Artificial Generativa ha llevado a directores y gerentes de tecnología a plantearse una misma meta: 'Queremos un ChatGPT que sepa todo sobre nuestra empresa'.
Sin embargo, el primer instinto suele ser el más costoso: pensar que se debe tomar un modelo (como GPT-4, Llama o Gemma) y 'reentrenarlo' (Fine-Tuning) con todos los documentos de la organización. Si bien esta técnica es poderosa, para el 90% de los casos de uso empresarial —como atención al cliente o búsqueda normativa— no solo es innecesaria, sino contraproducente.
Aquí te explico por qué la arquitectura RAG (Retrieval-Augmented Generation) es la estrategia ganadora.
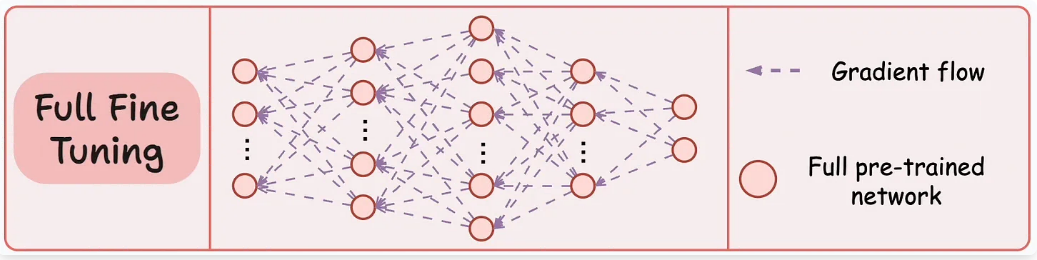
Comparativa: Memorización (Fine-Tuning) vs Búsqueda en biblioteca (RAG)
El problema de la 'Memoria' vs. la 'Búsqueda'
Imagina que contratas a un experto y le pides que memorice 1,500 manuales de operación (Fine-Tuning). Si mañana cambia una norma en la página 40 del manual 3, tendrás que volver a 'entrenar' al experto para que olvide el dato anterior y aprenda el nuevo. Esto es lento y computacionalmente costoso.
La arquitectura RAG, por otro lado, no le pide al modelo que memorice nada. Le da la capacidad de consultar. Funciona como un examen a libro abierto:
1. El usuario hace una pregunta.
2. El sistema busca en tu base de datos los párrafos relevantes.
3. La IA lee esos fragmentos y genera una respuesta precisa basada únicamente en esa información.
Caso real: Centralización normativa universitaria
Recientemente, implementé esta solución para resolver un problema común en el sector educativo: la dispersión de información. El reto era procesar más de 1,500 documentos PDF (muchos de ellos escaneados) con reglamentos, planes de estudio y calendarios.
Si hubiera optado por reentrenar un modelo, el costo de GPUs habría sido prohibitivo y el chatbot habría alucinado fechas o artículos inexistentes.
La solución técnica fue una arquitectura RAG:
• Digitalización: usé Tesseract OCR para extraer texto limpio de imágenes antiguas.
• Memoria Semántica: guardé la información en ChromaDB (una base de datos vectorial), permitiendo buscar conceptos, no solo palabras clave.
• Generación: conecté todo a Gemma (Google) mediante FastAPI.
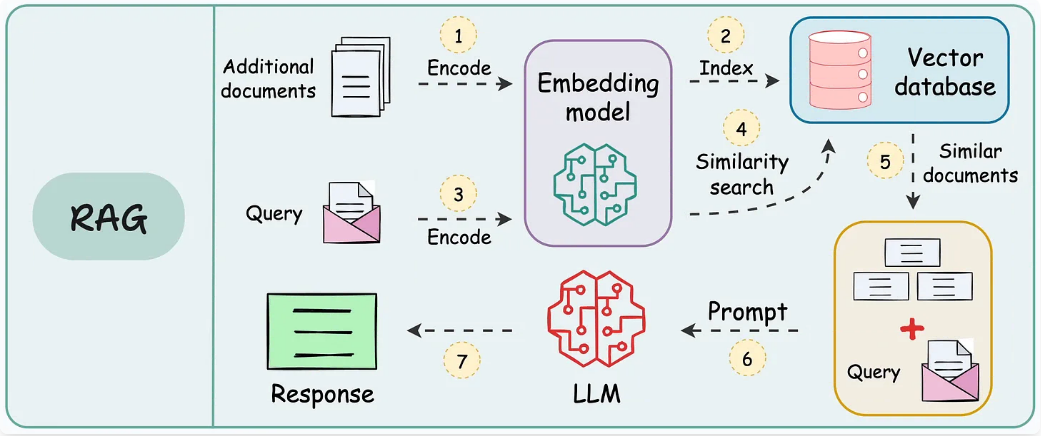
Diagrama para RAG
3 Razones para elegir RAG en tu empresa
Cero alucinaciones: al obligar al modelo a responder usando solo tus documentos, reduces drásticamente el riesgo de que la IA invente datos. Si la información no está en tus archivos, la IA dirá 'No lo sé', lo cual es vital en entornos financieros o legales.
Actualización inmediata: ¿cambió una política de precios hoy? Solo subes el nuevo PDF a la base de datos y listo. No hay que reentrenar nada.
Privacidad y costos: Puedes ejecutar modelos pequeños y eficientes localmente o en la nube privada, reduciendo la factura de tokens y manteniendo tus datos seguros.
Conclusión
Antes de invertir presupuesto en entrenar modelos masivos, analiza tu caso de uso. Si necesitas que tu IA sea creativa, entrena. Pero si necesitas que tu IA sea precisa, confiable y experta en tus propios datos, RAG es el camino.
Como Arquitecto de Soluciones, mi enfoque siempre es priorizar la herramienta que ofrece el mejor retorno de inversión, y hoy por hoy, RAG es el estándar de oro para la gestión del conocimiento empresarial.