El enemigo silencioso de tus modelos: Data Leakage (y cómo evitarlo)
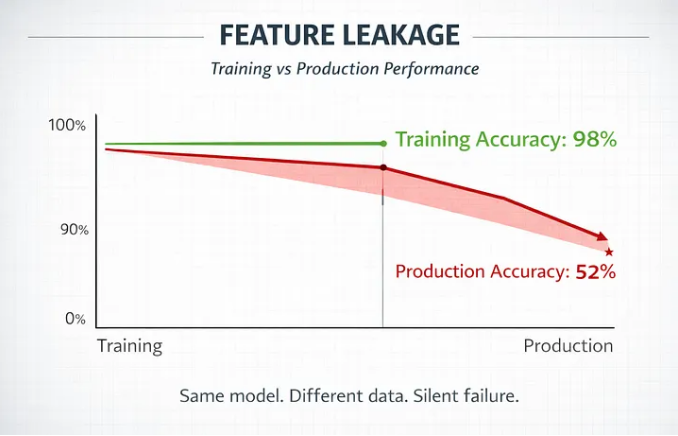
En el mundo de la Ciencia de Datos, existe una regla no escrita pero infalible: 'Si los resultados parecen demasiado buenos para ser verdad, probablemente lo son'.
Uno de los errores más comunes (y costosos) que veo en proyectos de Machine Learning es el Data Leakage o Fuga de Información. Ocurre cuando el modelo tiene acceso, durante su entrenamiento, a información que no debería ver o que no tendrá disponible en el mundo real. Es el equivalente a que un estudiante tenga las respuestas del examen anotadas en la mano antes de entrar al aula. Sacará 10 en la prueba, pero no sabrá nada cuando tenga que trabajar.
El caso del Scoring de Riesgo Crediticio
Hace poco, me tocó auditar y reingenierizar un modelo de riesgo para una financiera. El modelo original, desarrollado por un equipo previo, presumía métricas impresionantes: una precisión (Accuracy) cercana al 90% detectando a los malos pagadores.
Sin embargo, en la práctica, la cartera vencida no bajaba. ¿Qué estaba pasando?
Al revisar el código, encontré el culpable clásico: El preprocesamiento incorrecto de datos desbalanceados.
El equipo anterior había aplicado una técnica llamada SMOTE (para crear datos sintéticos y equilibrar las clases de buenos vs. malos pagadores) antes de dividir los datos en Entrenamiento y Prueba.

Error común: aplicar transformaciones a todo el dataset antes del split.
¿Por qué esto es grave?
Al aplicar SMOTE a todo el dataset primero, parte de la información de los datos de 'Prueba' se filtró en los datos de 'Entrenamiento' mediante la generación de ejemplos sintéticos muy similares. El modelo no estaba aprendiendo a distinguir deudores; estaba memorizando patrones geométricos que ya había visto.
La solución: arquitectura de pipelines robusta
Para corregir esto, implementé una reestructuración total del código utilizando Scikit-learn Pipelines e ImbPipeline.
La clave de la ingeniería de ML profesional es encapsular el proceso. Con los Pipelines, aseguramos que cualquier transformación (como la imputación de nulos, el escalado de variables o el balanceo con SMOTE) ocurra estrictamente dentro de cada pliegue de la Validación Cruzada (Cross-Validation).
El resultado fue un baño de realidad:
• La métrica bajó de ese 'falso 90%' a un AUC-ROC de 0.69 realista.
• Aunque el número parecía menor, este nuevo modelo era robusto y honesto.
• Al desplegarlo, el comportamiento en producción coincidió perfectamente con las pruebas, permitiendo automatizar decisiones con confianza real.
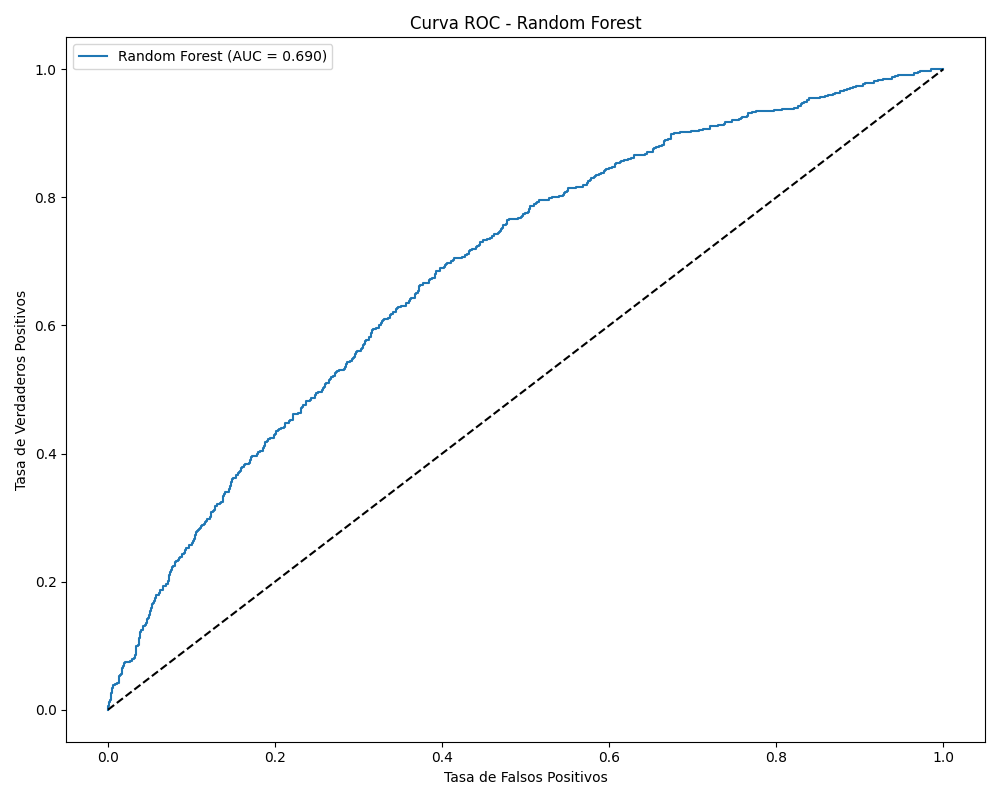
Curva ROC real del proyecto tras corregir el Data Leakage.
Conclusión
La diferencia entre un entusiasta de los datos y un Machine Learning Engineer no es conocer el algoritmo más moderno, sino entender la metodología experimental.
Evitar el Data Leakage requiere disciplina y una arquitectura de código limpia. En sectores críticos como el financiero o el médico, un modelo 'tramposo' no es solo un error técnico; es una pérdida millonaria o un riesgo ético inaceptable. Antes de celebrar un Accuracy perfecto, revisa tus tuberías.